Generate cooking recipes that guarantee food poisoning, with LSTM based libraries
Unless you are living in the Amazonian forest with no access to the Internet, there is literally no chance that you have not heard about the Deep Learning boom, of the last few years.
Training neural networks, that can make decisions, distinguish fake images or generate fake videos, in a relatively short time is becoming the norm.
It doesn’t all have to be scary though. Sometimes you can just have fun with all that power.
As part of today’s article, we will attempt to generate cooking recipes. But on the contrary to other articles, you don’t need to read 3 textbooks of deep learning, only the section below. In the next part, we will do the same work using pure deep learning code by setting up an LSTM.
LSTM and predicting “next values”
LSTM is a type of software (specifically, neural network) which can learn the pattern a sequence of data (you might hear that as time-series data) follows and thus predict the next “values” of the sequence.
Have you ever used Gmail? You might have seen the smart compose in action and if you haven’t here is a a great visual explanation of it.
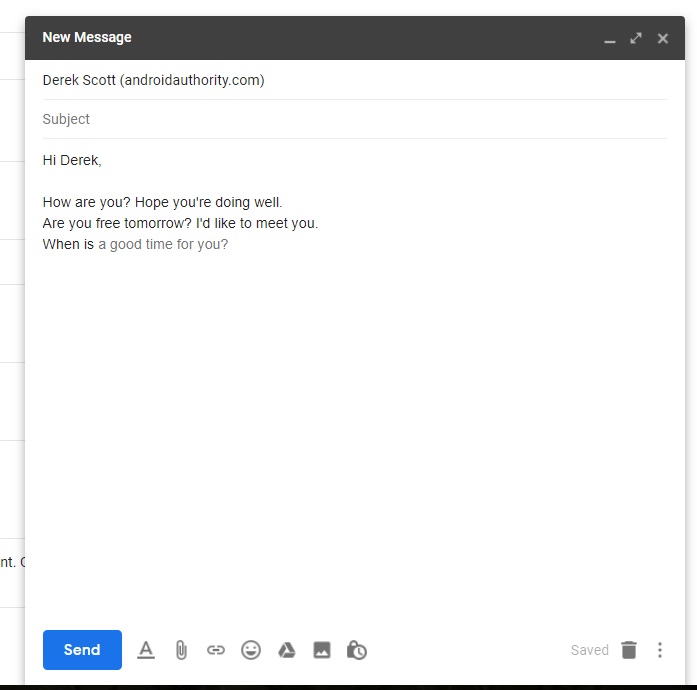 (Credits to androidauthority.com)
(Credits to androidauthority.com)
Gmail is probably using an LSTM here, which is trained on various sequences-mails. So it can safely predict that if the token “tomorrow?” is close enough to the token “when is” then the most probable set of “next tokens” is “a good time for you?”
Building our psychic
In this article, we are going to follow a coder’s approach, as I mentioned before. That means you don’t need any special knowledge of LSTM or deep learning to do the job
We are going to use a great library called
textgenrnn
```.
The steps to follow are:
- Setup the dev environment
- Prepare the data in a friendly format
- Call the library with your data
- Predict
## Setup the environment
First, we create a new virtualenv in a new folder
virtualenv -p python3 myenv And we source it source myenv/bin/activate
We install the library, as instructed from the README of the module
pip install tensorflow
pip install textgenrnn
Verify all went good by doing
import textgenrnn
Using TensorFlow backend.
Prepare the data in a friendly format
By glancing a bit in the datasets folder it looks like we want each sample on top. But according to the documentation it can be trained on any file so let’s create a recipes txt and try to train. Or maybe find something ready.
By Googling around, I have this wonderful page and downloaded the chili dataset. Let’s try to feed it as is and see how it goes. Here is an excerpt of the chili file
@@@@@ Now You're Cooking! Export Format
1981 WORLD CHAMP BUTTERFIELD STAGELINE CHILI
meats, chili
4 medium onions, minced
10-pound lean beef brisket, finely ch
1/4 cup oil
1 1/2 cloves garlic; minced
Lets train the model:
- Import the library
from textgenrnn import textgenrnn
- Initialize the model
textgen = textgenrnn()
- Start training by giving input
textgen.train_from_file('chili.txt', num_epochs=20)
The first results
The results that are returned, are quite a descent. But something is wrong. For example: If I run
textgen.generate()
I get
simmer for an hour. Originally slightly to cut into ground beef in brown. Add to the chili powder. Simmer for 1
This is incredible, especially if you think that the neural network we trained, knows nothing about language rules or speech patterns. It just understands character sequences. For more details, you can read this wonderful article from Andrej Karpathy
So, we need to change somehow the input format. If we open it, we see a lot of useless, for our training, stuff. For example,
Exported from Now You're Cooking! v5.93
By checking the examples of the library looks like it is expecting one training sequence per line.
We have the option to clean the chili.txt file either by hand or with python. Or get a more suitable dataset
Finding data for our training
Kaggle is the one-stop-shop for such purposes. By digging, a bit I found this dataset which looks structured and clean
Let’s transform the data into a format which is suitable to our needs (one recipe per line).
Here is how I did that and trained the network. Please note, that the network in order to be trained in a timely manner needs to leverage a GPU; because GPUs are very good at matrix multiplications, which is the foundation of neural network training.
So I have run this code in Google collab, though if you have a computer with an NVIDIA GPU you can do it locally too.
import json
from textgenrnn import textgenrnn
recipes_file = open('./recipes.json')
lines = recipes_file.readlines()
lines = [dict(json.loads(line)) for line in lines]
recipes = []
for line in lines:
features = []
description = line['Description']
ingredients = line['Ingredients']
method = line['Method']
for key in [description, ingredients, method]:
if key != None and len(key) > 0:
features.append(method)
recipes.append(features)
recipes_text = [ '.'.join(recipe_list[0]) for recipe_list in recipes]
write_to = open('recipes_text.txt', 'w')
write_to.write('\n'.join(recipes_text))
textgen = textgenrnn()
textgen.train_from_file('recipes_text.txt', num_epochs=20)
for i in range(5):
textgen.generate()
The results
Having trained RNNs/LSTMs before, I am impressed from both the quality of results the library returns, the speed it has (it took me about 2 minutes per epoch with the current dataset) and of course the ease of use.
Here is a result:
Put the sponge and sugar in a saucepan with the mustard and bake for 15 mins.
Meanwhile, make the frosted custard and stir to the sugar.
Stir the chopped chili flakes and stir in the flour, peel and some seasoning. Cook for a further 3 mins until the sugar has dissolved. Add the dressing and top
As I mentioned above, this is an incredible result, because the network doesn’t understand the meaning of words or even words. It just learns the character-sequence pattern of the dataset!!
And even though it is a readable paragraph, you can still get food poisoning. At least that’s what I would get if I ate sponge with sugar. :)
Read more if you are interested
Thank you for reading this article and I hope you enjoyed it. RNNs and LSTMs are complex technologies and it is worth investigating them a bit more, even if you are just happy with consuming such libraries (which is great, you don’t have to be an AI expert just to add some intelligence to your app).
Some resources worth checking out are: